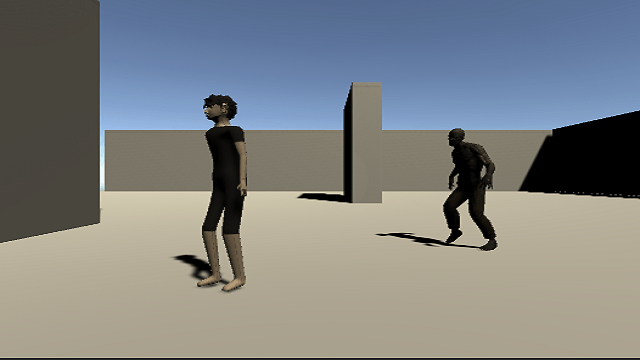
今回はUnityのML-Agentsを使って主人公を追いかける敵キャラクターを強化学習を使って学習させていこうと思います。
ML-Agentsに関してはこれまで、

で環境の作成をし、

でUnityのサンプルを使って実際に学習したゲームオブジェクトを動かす事をしました。
今回は自分で一からML-Agentsを使ったプロジェクトを作成してみようという感じです。
概要
操作キャラクターである主人公と主人公を追いかける敵キャラクターを作成し、敵キャラクターに強化学習を行って主人公キャラクターを追いかけるようにML-Agentsの設定やスクリプトの作成をしていきます。
操作キャラクターである主人公にはCharacterControllerコンポーネントの取り付け等、通常のキャラクターを操作する機能を取り付けるという今までと同じように作成します。
操作出来る主人公キャラクターの作成については既に他の記事にありますので詳細については省略します。
敵キャラクターにもCharacterControllerコンポーネントを取り付けコライダと移動機能を使います。
敵キャラクターの移動は従来のスクリプトを使ったものではなく、ML-Agentsを使って移動させるようにします。
敵キャラクターに取り付けるコンポーネントや作成するスクリプトの詳細については後で細かく見ていきます。
ゲームの舞台を作成する
まずは主人公キャラクターと敵キャラクターが移動をするゲームの舞台を作成します。
今回はゲームの舞台を狭くし、強化学習が早く終わるようにします。
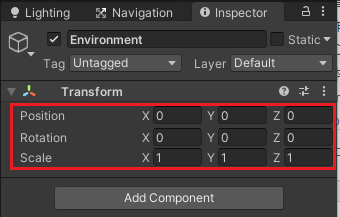
まずはヒエラルキー上で右クリックからCreate Emptyを選択し、名前をEnvironmentとします。
EnvironmentのインスペクタのTransformの歯車からResetを選択し、PositionのXYZが全て0、RotationのXYZが全て0、ScaleのXYZが全て1となるようにします。
このEnvironmentを一つのゲームの舞台の元とします。
これは複数の学習の舞台を同時に動かし、学習を早める為です。
その為に主人公や敵、障害物等をEnvironmentゲームオブジェクトの子要素に配置し、Environmentゲームオブジェクトを複製するだけでいいようにします。
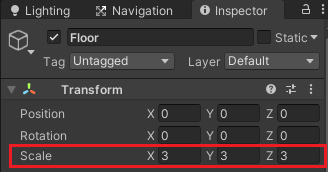
Environmentを選択した状態で右クリックから3D ObjectのPlaneを作成し、名前をFloorとします。
FloorのインスペクタでTransformのScaleのXYZを全て3とします。
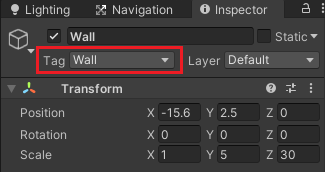
Environmentの子要素に3D ObjectのCubeをいくつか作成し名前をWallとして、Floorを囲むように配置したり、Floor上に障害物として置きます。
全てのWallゲームオブジェクトにはWallタグを作成し、設定しておきます。
ここで設定したWallタグはすぐには使いませんが、後でRayPerceptionSensor3Dコンポーネントを使った例の時に使います。
それぞれのWallのTransformのScale等を変更し配置してください。
ここまでのヒエラルキーは以下のようになります。
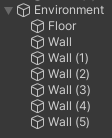
また実際に出来たゲームの舞台は以下のようになります。

まったく同じにする必要はありませんが、キャラクターがFloorから落ちないようにします。
これでゲームの舞台が出来ました。
操作出来る主人公キャラクターの作成
主人公キャラクターモデルをEnvironmentの子要素に配置します。
名前をPlayerと変更します。
PlayerのインスペクタでタグをPlayerに設定します。
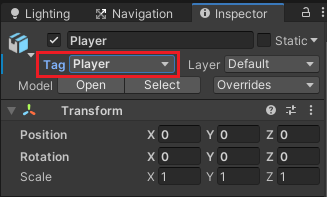
操作出来る主人公キャラクターにCharacterControllerコンポーネントを取り付け、コライダのサイズを調整します。
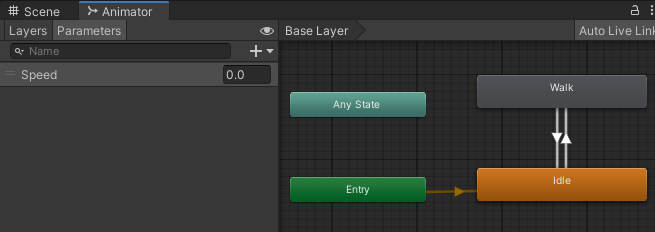
またAnimatorControllerを作成し、アニメーションパラメータにFloat型のSpeedを作成します。
Idel状態とWalk状態を作成し、
Idle→WalkはSpeedが0.1より大きい時
Walk→IdleはSpeedが0.1より小さい時
に遷移するように状態と遷移を作成します。
新しくMainCharacterというスクリプトを作成し、主人公キャラクターに取り付けます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | using System.Collections; using System.Collections.Generic; using UnityEngine; public class MainCharacter : MonoBehaviour { private CharacterController characterController; private Animator animator; [SerializeField] private float walkSpeed = 2f; private Vector3 velocity; // Start is called before the first frame update void Start() { characterController = GetComponent<CharacterController>(); animator = GetComponent<Animator>(); } // Update is called once per frame void Update() { if (characterController.isGrounded) { velocity = Vector3.zero; var input = new Vector3(Input.GetAxis("Horizontal"), 0f, Input.GetAxis("Vertical")); if (input.magnitude > 0f) { velocity = input.normalized * walkSpeed; //transform.LookAt(transform.position + input.normalized); transform.rotation = Quaternion.Lerp(transform.rotation, Quaternion.LookRotation(input.normalized), 6f * Time.deltaTime); animator.SetFloat("Speed", input.magnitude); } else { animator.SetFloat("Speed", 0f); } } velocity.y += Physics.gravity.y * Time.deltaTime; characterController.Move(velocity * Time.deltaTime); } } |
これで主人公キャラクターの作成が出来ました。
細かい部分は説明していませんが、
ここら辺は
辺りを参照してください
敵キャラクターの作成
敵キャラクターのモデルをEnvironmentの子要素に配置します。
わたくしの場合はゾンビのキャラクターを使用したので敵キャラクターの名前をZombieAgentとしました。
主人公キャラクターと同様にCharacterControllerコンポーネントの取り付けとAnimatorに作成したAnimatorControllerを設定します。
敵のキャラクターのAnimatorControllerは主人公キャラクターに設定したものと同じように状態と遷移を作成しアニメーションの設定をします。
敵の強化学習と行動のスクリプトを作成する
敵の強化学習と行動のスクリプトを新しくZombieAgentとして作成します。
この時点ではまだ敵キャラクターに取り付けないでください。
強化学習と行動のスクリプト概要
強化学習を行うゲームオブジェクトにはMonoBehaviourクラスを継承してクラスを作成するのではなくAgentクラスを継承して作成します。
AgentクラスのいくつかのメソッドをZombieAgentクラスでオーバーライドして定義し、そこに処理を書いていきます。
例えば以下のようなメソッドがあります。
Initialize
OnEpisodeBegin
CollectObservations
OnActionReceived
Heuristic
Initializeメソッドはエージェントの初期化時に呼ばれます。
OnEpisodeBeginはエピソード開始時に呼ばれます。
CollectObservationsはエージェントが観察するデータの収集時に呼ばれます。
OnActionReceivedは観察によって収集した情報を決定した後にアクションを起こす時に呼ばれます。またこの時の行動によって報酬を与えます。
Heuristicは学習状態でない時にテストプレイヤーがキャラクターを操作したりするときに使用します(他には模倣学習時に使います)。
学習を開始してから観察データの収集→行動を起こす
までが1ステップでAgentのMaxStepで指定したステップ数を繰り返し、MaxStepを超えたらエピソードが終了します。
また、スクリプト内でEndEpisodeメソッドを呼び出した場合もエピソードが終了します。
このステップ毎に報酬を与える事で敵に主人公キャラクターを追いかけるという事を学習させていきます。
この後スクリプトを作成していきますが、長いので少しずつ追加していきます。
クラスの定義とフィールド
まずはクラスの定義とフィールド宣言部分を作成します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | using System.Collections; using System.Collections.Generic; using Unity.MLAgents; using Unity.MLAgents.Sensors; using UnityEngine; public class ZombieAgent : Agent { private CharacterController characterController; private Animator animator; // 追いかけるターゲット [SerializeField] private Transform target; // 速さ [SerializeField] private float walkSpeed = 2f; // 速度 private Vector3 velocity; private void Start() { characterController = GetComponent<CharacterController>(); animator = GetComponent<Animator>(); } } |
Unity.MLAgentsとUnity.MLAgents.Sensorsをusingディレクティブで指定します。
ZombieAgentクラスはAgentクラスから継承して作成します。
targetは追いかける対象(主人公キャラクターであるPlayer)をインスペクタで設定します。
walkSpeedは歩く速さです。
velocityは移動速度です。
Startメソッドでは自身のコンポーネントを取得しています。
OnEpisodeBeginメソッドの作成
次にエピソード開始時の処理を行うAgentクラスのOnEpisodeBeginメソッドをオーバーライドします。
1 2 3 4 5 | public override void OnEpisodeBegin() { Reset(); } |
Resetメソッドを呼び出しているだけです。
Resetメソッドは後で作成します。
CollectObservationsメソッドの作成
次にデータの観察と収集を行うAgentクラスのCollectObservationsメソッドをオーバーライドします。
1 2 3 4 5 6 7 8 9 10 11 | // 観察の収集 public override void CollectObservations(VectorSensor sensor) { // ゲームの舞台サイズに合わせて正規化し観察に追加する sensor.AddObservation(target.localPosition / 15f); sensor.AddObservation(transform.localPosition / 15f); // 主人公の方向を正規化し観察に追加する var direction = (target.localPosition - transform.localPosition).normalized; sensor.AddObservation(direction); } |
今回の場合は敵キャラクターが主人公キャラクターを追いかけるので観察するデータとして自身(敵)のローカル位置と相手(主人公)のローカル位置、相手の方向を観察データに追加します。
観察データに追加する場合は必ずではないですが、なるべく正規化したデータを追加した方が学習が早くなるようです。
今回の場合はゲームの舞台であるFloorの縦横はそれぞれ15m(FloorのScaleでなく実際の長さ)なので位置は15で割り、相手の方向は.normalizedで正規化します。
追加するデータは必ずいつも同じ順番で追加する必要があるようです。
ここで追加している観察データが学習に必要なものでないとまったく学習しなかったり思い通りに学習してくれない状態になります。
なので、学習させようと思っている意図と関連したデータを追加する必要があります。
ここで追加したデータはtarget.localPositionとtransform.localPositionがVector3型なのでXYZの3つのデータが二つ、主人公の方向のデータもVector3なので合計9つの観察データを追加していることになります。
この数は後でBehavior ParametersコンポーネントのVector ObservationのSpace Sizeを設定する時に必要になります。
またプロパティやフィールドのデータはCollectObservationsメソッド内でsensor.AddObservationを使用して観察データを追加せずともプロパティやフィールドにObservableアトリビュートを付ける事で勝手にデータを収集してくれるようです。
Observableアトリビュートを付けた場合はBehavior ParametersコンポーネントのObservable Attribute Handlingを変更する必要があるかもしれません。
例えば速さフィールドを観察データに加える場合は以下のようにします。
1 2 3 4 5 6 | // 速さ [SerializeField] [Observable] private float walkSpeed = 2f; |
Observableアトリビュートを取り付ける場合は
1 2 3 | using Unity.MLAgents.Sensors.Reflection; |
を指定しておきます。
この場合はBehavior ParametersコンポーネントのVector ObservationのSpace Sizeの数に加える必要はないようです。
CollectObservationsメソッドで観察データを追加せず、RayPerceptionSensor3DやRayPerceptionSensor2D等を使っても観察データの収集が出来ます。
RayPerceptionSensor3Dコンポーネントは後で使ってみます。
こちらの場合もBehavior ParametersコンポーネントのVector ObservationのSpace Sizeの数に加える必要はないようです。
現時点ではCollectObservationsで追加したデータ数をBehavior ParametersコンポーネントのVector ObservationのSpace Sizeに設定するということです。
ObservableアトリビュートやRayPerceptionSensor系コンポーネントを使った場合は数については考慮しなくていいという感じです。
OnActionReceivedメソッドの作成
次に観察したデータを元に起こす行動を起こすメソッドであるAgentクラスのOnActionReceivedメソッドをオーバーライドして作成します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | // アクションの受け取りと報酬を与える public override void OnActionReceived(float[] vectorAction) { // MaxStepを分母にして1ステップ毎にマイナス報酬を与える AddReward(-1f / MaxStep); // 移動データの作成 var input = new Vector3(vectorAction[0], 0f, vectorAction[1]); // キャラクターが接地している時だけ移動 if (characterController.isGrounded) { velocity = Vector3.zero; if (input.magnitude > 0f) { // キャラクターの向きは徐々に変える transform.rotation = Quaternion.Lerp(transform.localRotation, Quaternion.LookRotation(input.normalized, Vector3.up), 6f * Time.deltaTime); velocity = transform.forward * walkSpeed; animator.SetFloat("Speed", input.magnitude); } else { animator.SetFloat("Speed", 0f); } } velocity.y += Physics.gravity.y * Time.deltaTime; characterController.Move(velocity * Time.deltaTime); // 主人公と自身(敵)の距離が1.8mより短ければ1の報酬を与える if (Vector3.Distance(target.localPosition, transform.localPosition) < 1.8f) { AddReward(1f); EndEpisode(); } // なんらかの影響でFloorから転落し位置が-5より下になったら-0.1の報酬を与える if (transform.localPosition.y < -5f) { AddReward(-0.1f); EndEpisode(); } } |
vectorActionにfloat型の配列が渡ってきますが、これはBehavior ParametersコンポーネントのVector Actionで指定したSpace Size分のデータが渡ってきます。
AgentクラスのAddRewardメソッドで報酬を与える事が出来ますが、敵には主人公に早く追いついてほしいので、毎ステップマイナス報酬を与える事にします。
次にvectorActionに渡ってきたデータを元に入力データinputを作成します。
キャラクターの移動処理に関しては通常の処理です。
キャラクターが向きを変える時は現在の回転から入力データinputの方向の回転の方向に徐々に回転させています。
Quaternion.LookRotationで入力の方向の回転を計算しています。
キャラクターの向きの処理に関しては他の記事に記載しているので説明は省略させて頂きます。
回転スピードに6というマジックナンバーを使用していますが、これはプロパティやフィールドで定義して使った方がいいと思います。(-_-)
自身(敵)と相手(主人公)との距離が1.8mより近くなった場合に1の報酬を与えます。
それ以外に敵キャラクターがなんらかの理由でFloorから転落し、TransformのYの位置が-5より下になったら-0.1の報酬を与えます。
与える報酬に関して
今回与えている報酬は1、-0.1、等ですが、報酬は-1~1の間ぐらいで与えると良いようです。
UnityのサンプルのPushBlockでは報酬を5とか与えているので、必ずしも-1~1の間というわけではないですが、大体この間で与えるといいのかもしれません。
Resetメソッドの作成
次にデータのリセットを行うResetメソッドを作成します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | // データの初期化メソッド public void Reset() { velocity = Vector3.zero; characterController.enabled = false; transform.localPosition = new Vector3(-2f, 1.5f, 0f); characterController.enabled = true; var targetCharacterController = GetComponent<CharacterController>(); targetCharacterController.enabled = false; target.localPosition = new Vector3(Random.Range(-13f, 13f), 0f, Random.Range(-13f, 13f)); targetCharacterController.enabled = true; } |
Resetメソッドはエピソード開始時に呼ぶので敵キャラクターや主人公キャラクターの位置を変更する処理を記述しています。
位置を変更する時は一旦CharacterControllerコンポーネントを無効化してから位置を変え再度有効にしています。
これはCharacterControllerが有効なまま位置を変更しても反映されないことがあるからです。

Heuristicメソッドの作成
次は自分で操作して機能を確認する時の為のAgentクラスのHeuristicメソッドをオーバーライドして作成します。
1 2 3 4 5 6 7 | // 自分で操作 public override void Heuristic(float[] actionsOut) { actionsOut[0] = Input.GetAxis("Horizontal"); actionsOut[1] = Input.GetAxis("Vertical"); } |
actionOutに入力データをそのまま入れます。
このメソッドを作成しておくと、Behavior ParametersコンポーネントのBehavior TypeがHeuristic OnlyまたはDefaultで学習状態でない時に自分で操作して敵キャラクターを移動出来、機能の確認をすることが出来ます。
これでスクリプトの作成が終わりました。
ZombieAgentスクリプトの取り付けと設定
ZombieAgentスクリプトが出来たのでZombieAgentゲームオブジェクトに取り付けます。
ZombieAgentスクリプトを取り付けると同時にBehavior Parametersコンポーネントも取り付けられます。
これはAgentクラスにRequireComponentアトリビュートでBehaviorParametersスクリプト(コンポーネント)が指定してあるからです。
Behavior Parametersの設定
ZombieAgentスクリプトを取り付けた時に同時に取り付けられたBehavior Parametersコンポーネントの設定項目について見ていきます。
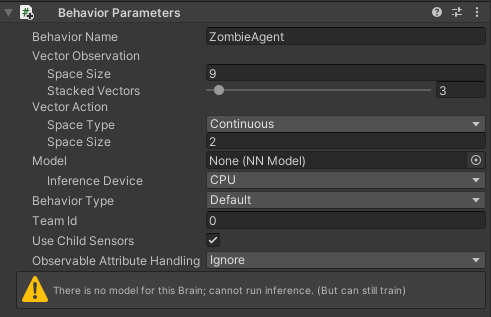
Behavior Nameは動作の識別子でここで指定した名前と同じ名前の学習エージェントは同じデータを共有します。
今回はZombieAgentという名前を設定しました。
Vector Observationは観察するデータに関しての設定です。
Space SizeはCollectObservationsメソッドで追加した観察データの数を設定します。
今回は9つのデータを追加するので9を設定しました。
Stacked Vectorsは観察データを過去の何ステップ分を保持しておくかのデータです。
今回は過去の3ステップ分を保持しておくことにします。
Vector Actionは行動のVectorデータに関しての設定です。
Space TypeのDiscreteは離散データで-1、0、1等の整数データでContinuousは浮動小数点データです。
Discreteを設定した場合
Branches Sizeで何個のデータ配列を使用するかで、その個々が何個のデータを持っているかをBranch 番号 Sizeで設定します。
Space TypeをDiscreteにした例は記事の最後に記します。
今回はSpace TypeはContinuousにし、Space SizeはXとZ方向の入力データの2にします。
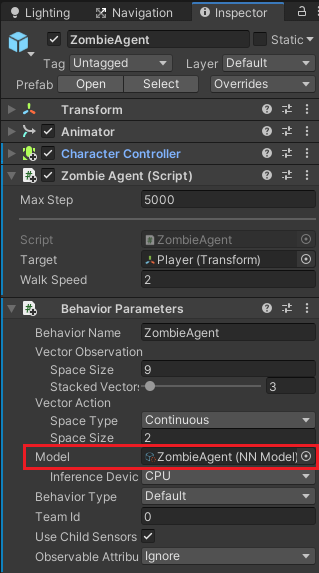
Modelには実際に学習させたデータを設定しますが、まだ学習していないので現時点では設定しません。
Inference DeviceはCPUとGPUどちらを使って学習するかです。今回はCPUにします。
Behavior Typeは動作のタイプで
Inferenceは学習データを使って推論でエージェントを動かします。
HeuristicはHeuristicメソッドで設定したとおり入力してエージェントを動かします。
Defaultだと学習中はInferenceにし、学習をしていない時にプレイボタンを押したらHeuristicにします。
Team Idはセルフプレイ時のチームの定義に使用するようです(使ってないのでわからない)。
おそらく学習データを使ったエージェントと対戦するような場合に値を変更して使うのかも?
Use Child Sensorsは敵キャラクターの子要素にあるセンサーコンポーネント(RayPerceptionSensor3D等)を使用するかどうか
Observable Attribute Handlingは観察可能な属性の取り扱いの設定で
Ignoreは無視
Exclude Inheritedは継承を除外、自身のクラスのみ調べる
Examine Allは全てを調べる
になります。
おそらくObservableアトリビュートを取り付けたプロパティやフィールドの扱いについてです。
今回はObservableアトリビュートを付けたプロパティやフィールドの観察は行わないのでIgnoreにしています。
ZombieAgentのインスペクタの設定
次にZombieAgentのインスペクタの設定をします。
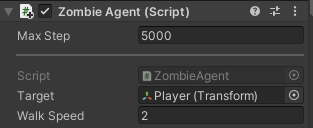
MaxStepに5000を設定し、観察→決定→行動の最大ステップ数を5000にします。
最大ステップ数を超えるとエピソードが終了し新しいエピソードが開始されOnEpisodeBeginメソッドが呼ばれます。
Targetには追いかける対象であるPlayerゲームオブジェクトを設定します。
Decision Requesterコンポーネントの取り付け
ZombieAgentのインスペクタのAdd ComponentからMl Agents→Decision Requesterを取り付けます。
Decision Requesterコンポーネントは決定をリクエストします。
Decision Periodは決定の周期です。値が大きいほど決定の頻度が多くなります。
Take Actions Between Decisionsにチェックを入れると決定の間にアクションを取ります。
観察→決定→アクション→報酬
というステップを繰り返します。
Decision Requesterコンポーネントを取り付けていない場合はスクリプトでAgent.RequestDicisionメソッドを呼び出して決定をする必要があります。
これで機能が出来上がりました。
機能を実行してみる
とりあえず機能が出来たのでUnityエディターのプレイボタンを押して実行し、敵を動かして主人公に接近し近づくと位置がリセットされるのを確認してください。
ただこのまま実行するとPlayerゲームオブジェクトが動くので一旦PlayerのMainCharacterコンポーネントのチェックを外し入力で動かないようにしておきます。
実行してみると以下のように主人公に近づくとエピソードが終了し、新しい位置にセットされ新しいエピソードが開始されるのを確認出来ました。
これは作った機能を確認するだけ学習はしていません。
確認が終了したらPlayerのMainCharacterコンポーネントを有効化しておいてください。
学習環境を複製する
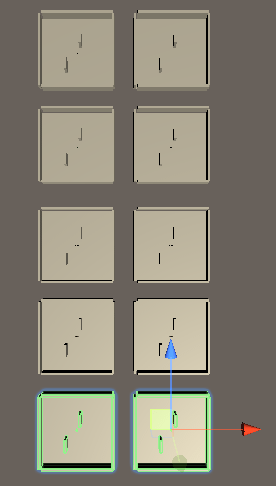
機能は出来たので後は敵キャラクターに学習させるだけですが、ひとつの環境だけで学習をさせると時間がかかるので、Environmentを複製して10個にします。
Environmentを選択し、Ctrl+Dキーを押すとEnvironmentゲームオブジェクトとその子要素が複製されます。
複製されたEnvironment(1)を横に移動させます。
次は元のEnvironmentとEnvironment(1)をCtrlキーを押しながら両方選択し、Ctrl+Dキーを押して複製し、そのまま矢印を操作し移動させるという事を繰り返して複製したり移動させたりをします。
ヒエラルキーは以下のようになりました。
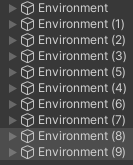
以下のように10個の環境が出来ました。
学習設定ファイルを作成する
学習設定ファイルを一から作成するのは大変なので、UnityのサンプルのPushBlockの設定ファイルをコピーして使います。
Unityツールチップをデスクトップにファイル展開しているとすれば
C:\Users\ユーザー名\Desktop\ml-agents-release_8\ml-agents-release_8\config\ppo
にあるPushBlock.yamlをコピーしデスクトップに貼り付けます。
名前をZombieAgent.yamlに変更し、中身も少し変更します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | behaviors: ZombieAgent: trainer_type: ppo hyperparameters: batch_size: 128 buffer_size: 2048 learning_rate: 0.0003 beta: 0.01 epsilon: 0.2 lambd: 0.95 num_epoch: 3 learning_rate_schedule: linear network_settings: normalize: false hidden_units: 256 num_layers: 2 vis_encode_type: simple reward_signals: extrinsic: gamma: 0.99 strength: 1.0 keep_checkpoints: 5 max_steps: 5.0e6 time_horizon: 64 summary_freq: 5000 threaded: true |
behaviorの後をZombieAgentとします(これはUnityのBehavior ParametersのBehavior Nameと一致させます)。
max_stepsを5.0e6とし10個の学習ステージで全部で5000000回(実際にこんなにステップを実行する必要はないが・・)のステップを行うようにします。
またsummary_freqを5000としコマンドプロンプトに表示される経過を5000ステップ毎に行う事にします。
これは現在の平均報酬を定期的に確認したい為です。
細かい設定については以下を参照してください。
別の記事に書こうと思いましたが思いのほか専門的な感じなのでやめました・・・・(^_^;)
学習を開始する
機能が出来たので学習をさせてみましょう。
学習をさせるやり方は前回の記事でやったのでおさらいにサラッと書いておきます。
Anacondaのコマンドプロンプトでデスクトップに移動します。
コマンドプロンプトは以下のようになっているはずです。
(base) C:\Users\ユーザー名\Desktop>
以下のようにコマンドを打ちます。
conda activate ML-Agentの環境名
ML-Agentの環境名は環境を作った時に付けた名前です。
わたくしの記事ではmlagentsという名前で作成しました。
ここまででコマンドプロンプトは以下のようになっています。
(mlagents) C:\Users\ユーザー名\Desktop>
以下のようにコマンドプロンプトにコマンドを打ち学習を開始させます。
mlagents-learn ./ZombieAgent.yaml –run-id ZombieAgent_01
コマンドプロンプトにUnityEditorのプレイボタンを押すとトレーニングが開始されるというのが表示されたらUnityエディターのプレイボタンを押します。
以下のように敵が主人公を追いかけるように学習していきます。
学習時はUnityのTimeScaleが20になります。
通常のTimeScaleで学習の様子を確認する場合はUnityメニューのEdit→Project Settings→TimeのTime Scaleを1にすることで通常のスピードで敵が学習するのを確認出来ます。
ただTimeScaleを1にすると当然学習スピードが落ちますので特に変更する必要はありません。
Unityエディターのプレイボタンを再度押すか、コマンドプロンプトでCtrl+Cキーを押すとと学習が終了します。
今回は以下のように5分ほど学習させました。

最初は報酬が得られていませんが、だんだん1に近づいています。
今回の場合はどんだけがんばっても1ステップで得られる報酬の最大が1なので平均報酬が1に近づくほど安定して主人公に到達出来ているという事になります。
学習結果を使って敵の動きを確認する
学習結果を使って敵の動きを確認してみます。
学習結果は以下のフォルダにZombieAgent.nnという名前で作成されます。
C:\Users\ユーザー名\Desktop\results\ZombieAgent_01
ZombieAgent.nnファイルをUnityのAssetsフォルダにドラッグ&ドロップします。
学習の為に複製したEnvironmentは最初のひとつを除きインスペクタの名前の横のチェックを外し非アクティブにします。
ZombieAgentゲームオブジェクトのBehavior ParametersのModelにドラッグ&ドロップして設定します。
Unityエディターのプレイボタンを押して敵が主人公を追いかけるかどうかを確認します。
以下のように主人公を移動させても敵が追いかけてきます。
RayPerceptionSensor3Dを使って観測する
エージェントに取り付けたスクリプトのCollectObservationsメソッド内で自分で観測するデータを追加する他に、RayPerceptionSensor3Dコンポーネントを追加することでも指定したタグを持つゲームオブジェクト(コライダ)をレイで探しそのデータを観測することが出来ます。
試しに敵にRayPerceptionSensor3Dコンポーネントを取り付けて観測出来るようにしてみます。
ZombieAgentゲームオブジェクトを選択し、右クリックからCreate Emptyを選択し空のゲームオブジェクトを作成して、名前をRaySensorとします。
RaySensorのインスペクタのAdd ComponentからML Agents→Ray Perception Sensor 3Dを取り付けます。
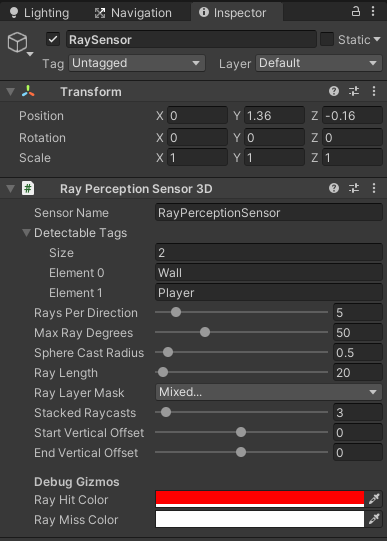
Sensor Nameはこのセンサーの名前です。
Detectable Tagsはセンサーが感知するタグを設定します。今回はWall(壁)とPlayer(主人公)を設定しました。
Rays Per Directionは方向に対するレイの数を設定します。
Max Ray Degreesはレイの角度(全てのレイの範囲角度)を設定します。
Sphere Cast Radiusはレイが感知した部分で判定する範囲である球の半径を設定します。
Ray Lengthはレイの長さを設定します。
Ray Layer Maskはどのレイヤーを判断するかです。
Stacked Raycastsは過去の観測データを何個分保持するかです。
Start Vertical Offsetはレイのスタート位置の垂直方向のオフセット値です。
End Vertical Offsetはレイのエンド位置の垂直方向のオフセット値です。
Debug Gizmosの
Ray Hit Colorはレイがヒットした場合の色を設定します。
Ray Miss Colorはレイがヒットしていない場合の色を設定します。
RaySensorゲームオブジェクトを敵キャラクターからレイを出す場所に移動させると以下のようにシーンビューでレイのギズモが表示されWallタグを設定した壁やPlayerタグを設定した主人公にヒットしているのがわかります。

RayPerceptionSensor3Dコンポーネントを使用した観測データの数はBehavior ParametersのVector ObservationsのSpase Sizeに追加する必要はありません。
RayPerceptionSensor3Dコンポーネントを使うとレイがぶつかった部分のデータの観測も出来るので色々使えそうですね。
ただ現時点でわたくしにはどう使っていいやらわかりませんが・・・・(^_^;)
Unityのサンプルを見てどう使っているか確認してみてください。(._.)
Behavior ParametersのVector ActionのSpace TypeをDiscreteにした場合
番外編としてBehavior ParametersのVector ActionのSpace TypeをDiscreteにした場合の設定やスクリプトについても見ておきます。
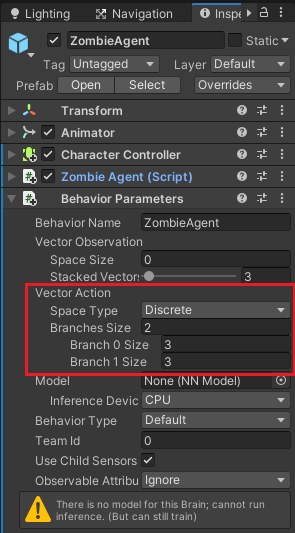
まずはZombieAgentのBehavior ParametersのVector ActionのSpace TypeをDiscreteにし、Branches Sizeを2、Branch0 Sizeを3、Branch1 Sizeを3とします。
これは前後の入力は入力していない場合、前に入力した場合、後ろに入力した場合の3パターン
左右の入力は入力していない場合、右に入力した場合、左に入力した場合の3パターン
を用意します。
次にZombieAgentスクリプトのOnReceiveActionメソッドとHeuristicメソッドを変更します。
まずはHeuristicメソッドです。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | public override void Heuristic(in ActionBuffers actionsOut) { var discreteActionsOut = actionsOut.DiscreteActions; discreteActionsOut[0] = 0; discreteActionsOut[1] = 0; // 前後移動 if (Input.GetKey(KeyCode.UpArrow)) { discreteActionsOut[0] = 1; } else if (Input.GetKey(KeyCode.DownArrow)) { discreteActionsOut[0] = 2; } // 左右移動 if (Input.GetKey(KeyCode.RightArrow)) { discreteActionsOut[1] = 1; } else if (Input.GetKey(KeyCode.LeftArrow)) { discreteActionsOut[1] = 2; } } |
前後と左右の動きをそれぞれ判断出来るようにBehavior ParametersのVector ActionでBranches Sizeを2としたので、それぞれの移動に個別にアクションを設定します。
上のスクリプトの場合は0が入力なしで、
上の矢印キーを押した場合はdiscreteActionOut[0]に1、下の矢印キーの場合は2を入れ、
右の矢印キーを押した場合はdiscreteActionOut[1]に1、左の矢印キーの場合は2を入れます。
これに対応してOnActionReceivedメソッドも書き換えます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | public override void OnActionReceived(ActionBuffers actions) { AddReward(-1f / MaxStep); var movementForward = actions.DiscreteActions[0]; var movementSide = actions.DiscreteActions[1]; var input = Vector3.zero; if (movementForward == 1) { input += Vector3.forward; } else if (movementForward == 2) { input += -Vector3.forward; } if (movementSide == 1) { input += Vector3.right; } if (movementSide == 2) { input += -Vector3.right; } // 以下はContinuousと同じ処理なので省略 } |
引数はActionBuffers型のactionsの受け取りに変更します。
actions.DiscreteActions[0]が前後の動き、actions.DiscreteeActions[1]を左右の動きに対応し、前後と左右でそれぞれ入力値を計算出来るようにしています。
入力はtransform.forwardを使ってしまうとキャラクターを回転した時にtransform.forwardが常に変わってしまうのでVector3.forward等のワールド空間の前後を使っています。
終わりに
この記事を書くまでに環境の作成からUnity側でのコンポーネントの設定やスクリプトの作成、学習をさせる方法等、様々な事柄を理解する必要があり時間がかかりました。
観測データに意味のないデータを入れたり報酬をうまく設定せずにトレーニングを開始し、一向に学習をしてくれない状態になるということも多々あります。(^_^;)
いきなり細かい設定の学習をさせるより小さい機能で試して少しずつ複雑な学習をさせるように作っていく方がいいかもしれませんね。
使いこなすまでには全然いかないです。((+_+))
Unityツールキットのサンプルでは色々な事をやっているのでそちらもどうなっているのか見てみるのも面白いかもしれません。
次回があるとしたら模倣学習についても記事に出来たらいいなぁと思います。(._.)

