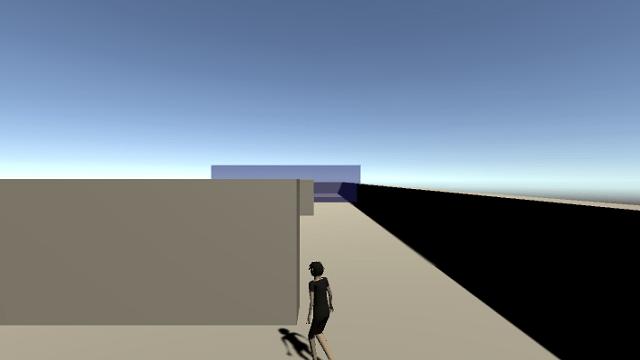
今回はUnityのML-Agentsを使って自分でキャラクターを動かして作ったデモの動きを模倣して学習するキャラクターを作ってみたいと思います。
今回の記事までにML-Agentsを使って以下の記事のような事をしてきました。



今回の記事でわからない部分は上の記事を参照してみてください。
機能の概要
今回はまず自分でキャラクターを操作して観察データとアクションデータのデモファイルを作成します。
デモファイルの作成はML-AgentsのDemonstration Recorderコンポーネントをエージェントゲームオブジェクトに取り付けて行います。
デモファイルが出来たら通常通りの学習の実行を行うとデモファイルのデータを使って模倣学習を行います。
学習用の設定ファイルyamlファイルの中身は模倣学習用のパラメータ設定を追加します。
学習の舞台を作成する
まずはキャラクターを操作したり学習をさせる舞台を作成します。
まずはCreate Emptyで空のゲームオブジェクトを作成し名前をEnvironmentとし、インスペクタのTransformの3つの点の部分を押しResetを選択してデフォルト値にします。
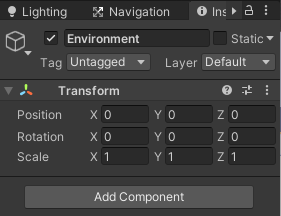
Environmentを選択した状態で右クリックから3D Object→Planeを選択し、名前をFloorとします。
TransformのScaleのXを2、Zを10とします。

次はFloorを覆う外壁とFloorの道中に置く障害物の作成をします。
全て右クリックから3D Object→Cubeを選択し作成していきます。
外壁は縦2、横2、障害物は3作りますので合計7のCubeを作成します。
外壁の縦の長い部分のTransformのScaleはYを5、Zを100とします。
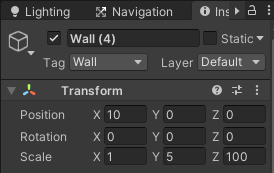
外壁の横の部分のTransformのScaleのXは20、Yは5とします。
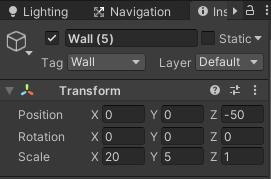
障害物のTransformのScaleはXは8、Yを3とします。
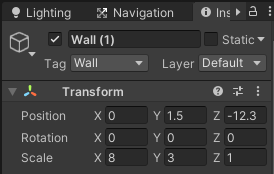
縦横の外壁と障害物のTransformのPositionはそれぞれ調整してください。
また7つのゲームオブジェクトにはそれぞれWallタグを作成し設定しておきます。
ここまでの階層は以下のようになります。
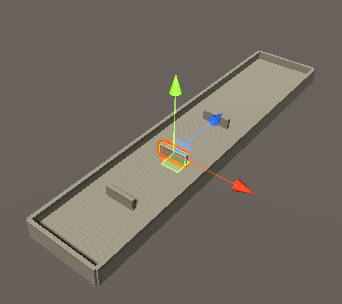
実際の画像は以下のようになります。
次にキャラクターが移動すると報酬を得てエピソードを終了する領域を作成します。
Cubeを使って作成し名前をGoalとし、マテリアルには半透明なものを設定し、インスペクタのBox ColliderコンポーネントのIs Triggerにチェックを入れ衝突をしないようにし、検知エリアとして使います。
Transformは舞台に合わせて調整してください。
またGoalタグを作成し設定します。
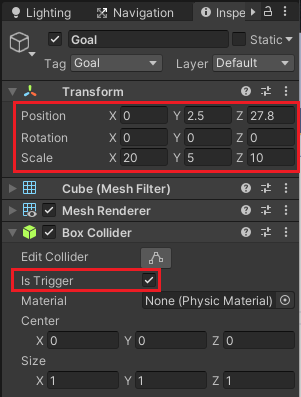
わたくしの場合は半透明な青色のマテリアルを設定したので以下のようになりました。

エージェントの作成
次は舞台を移動するキャラクターの作成です。
キャラクターにはCharacterControllerコンポーネントを取り付けコライダのサイズを調整します。
キャラクターに設定するAnimatorControllerはアニメーションパラメータにFloat型のSpeedを作成し、
Idle状態とWalk状態を持ち、Speedが0.1より上の時はIdle→Walk、0.1より下の時はWalk→Idleへと遷移するように作ってください。
キャラクターゲームオブジェクトの名前はImitationLearningCharacterとします。
エージェントスクリプトの作成
キャラクターに設定するエージェントスクリプトは前回の記事で作成したものとほとんど同じなので詳細は割愛します。
新しくImitationLearningCharacterスクリプトを作成します。
スクリプトは完成してからキャラクターに取り付けます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 | using System.Collections; using System.Collections.Generic; using Unity.MLAgents; using Unity.MLAgents.Actuators; using Unity.MLAgents.Sensors; using Unity.MLAgents.Sensors.Reflection; using UnityEngine; public class ImitationLearningCharacter : Agent { private CharacterController characterController; private Animator animator; // 速さ [SerializeField] private float walkSpeed = 10f; // 速度 private Vector3 velocity; // 初期位置 private Vector3 initCharacterPosition; // ゴールゲームオブジェクト [SerializeField] private Transform goal; public override void Initialize() { characterController = GetComponent<CharacterController>(); animator = GetComponent<Animator>(); initCharacterPosition = transform.localPosition; } public override void OnEpisodeBegin() { Reset(); } // 観察の収集 public override void CollectObservations(VectorSensor sensor) { // 正規化する var normalizedPosition = new Vector3(transform.localPosition.x / 20, transform.localPosition.y, transform.localPosition.z / 100); // 観察に追加 sensor.AddObservation(normalizedPosition); sensor.AddObservation(new Vector3(velocity.x, 0f, velocity.z).normalized); sensor.AddObservation(goal.localPosition - transform.localPosition); } // アクションの受け取りと報酬を与える public override void OnActionReceived(float[] vectorAction) { // MaxStepを分母にして1ステップ毎にマイナス報酬を与える AddReward(-1f / MaxStep); // 移動データの作成 var input = new Vector3(vectorAction[0], 0f, vectorAction[1]); // キャラクターが接地している時だけ移動 if (characterController.isGrounded) { velocity = Vector3.zero; if (input.magnitude > 0f) { // キャラクターの向きは徐々に変える transform.rotation = Quaternion.Lerp(transform.localRotation, Quaternion.LookRotation(input.normalized, Vector3.up), 6f * Time.deltaTime); velocity = transform.forward * walkSpeed; animator.SetFloat("Speed", input.magnitude); } else { animator.SetFloat("Speed", 0f); } } velocity.y += Physics.gravity.y * Time.deltaTime; characterController.Move(velocity * Time.deltaTime); // なんらかの影響でFloorから転落し位置が-5より下になったら-0.1の報酬を与える if (transform.localPosition.y < -5f) { AddReward(-0.1f); EndEpisode(); } } // データの初期化メソッド public void Reset() { velocity = Vector3.zero; characterController.enabled = false; transform.localPosition = initCharacterPosition; characterController.enabled = true; } // 自分で操作 public override void Heuristic(float[] actionsOut) { actionsOut[0] = Input.GetAxis("Horizontal"); actionsOut[1] = Input.GetAxis("Vertical"); } } |
エピソードを終了したら最初の位置に戻したいのでinitCharacterPositionに開始時のキャラクターの位置を入れておきます。
goalはインスペクタでGoalゲームオブジェクトをドラッグ&ドロップして設定します。
Initializeメソッドはエージェント開始時に1回だけ呼ばれるのでそこでコンポーネントの取得をします。
OnEpisodeBeginメソッドはエピソード開始時に呼ばれるのでそこでデータのリセットを行います。
CollectObservationsメソッドでは観察データの追加を行っています。
今回の場合はキャラクターの位置を舞台のサイズに合わせて正規化したVector3の値と、キャラクターの速度のVector3の値、ゴールの方向のVector3の値を追加しています。
OnActionReceivedメソッドではアクションの実行と報酬を与えています。
Resetメソッドはキャラクターの位置を元の位置に戻しています。
Heuristicメソッドは自分でキー操作する時に呼び出すメソッドです。
ここまで出来たらキャラクターにImitationLearningCharacterスクリプトを取り付け設定をします。

キャラクターにはPlayerタグを設定し、AnimatorにAnimatorControllerを設定しApply Root Motionのチェックを外します。
Behavior ParametersのBehavior NameにはImitationLearningCharacterという名前を付けます。
Vector Observationはスクリプトで設定した観察数なのでSpace Sizeを9、Stacked Vectorsは過去のデータをどれだけ保持しておくかなので5にします。
Vector ActionはContinuousにし連続的な数値を扱えるようにします。今回の場合はSpace Sizeを2にし、移動のfloat値を2つ使います。
ImitationLearningCharacterではMax Stepを5000にし、GoalにGoalゲームオブジェクトをドラッグ&ドロップします。
Decision Requesterコンポーネントの取り付け
次にImitationLearningCharacterのインスペクタのAdd ComponentからML Agents→Decision Requesterコンポーネントを追加します。
これはどれだけの頻度決定を下すかを設定するものです。
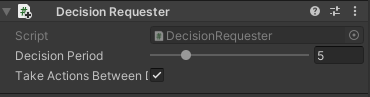
これは初期設定のまま使用します。
このコンポーネントがないとエージェントは学習をしません(決定をしてアクションを起こせない為)。
Demonstration Recorderコンポーネントの取り付け
次にエージェントの観察とアクションをデモファイルに保存してくれるコンポーネントDemonstration Recorderを取り付けます。
ImitationLearningCharacterのインスペクタのAdd ComponentからML Agents→Demonstration Recorderを選択し取り付けます。
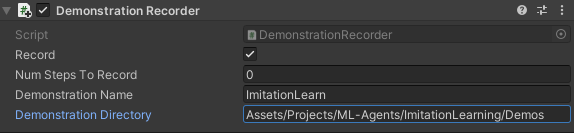
Recordにチェックを入れるとUnityのエディターのプレイボタンを押した時にエージェントの観察とアクションを記録します。
Num Steps To Recordは何ステップを記録するかの数値で、0を設定するとUnityエディターのプレイボタンを押してから再度プレイボタンを押すまでずっと記録します。
Demonstration Nameはデモファイルの名前です。
Demonstration Directoryはデモファイルまでのパスを設定します。
Ray Perception Sensor 3Dコンポーネントの使用
ImitationLearningCharacterスクリプトでキャラクターの位置、キャラクターの速度、ゴールの方向のVector3型の9つの値を観察に追加しましたが、それとは別にレイを使って衝突した物理的な物体の観察データも収集出来るようにしておきます。
ImitationLearningCharacterゲームオブジェクトを選択した状態で右クリックからCreate Emptyを選択し、名前をRaySensorとします。
RaySensorゲームオブジェクトの位置を少し上に移動し、キャラクターの目の辺りに移動させます。
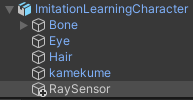
インスペクタのAdd ComponentからML Agents→Ray Perception Sensor 3Dを選択し取り付けます。
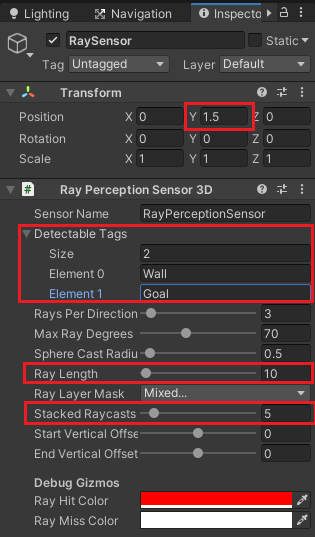
Detectable TagsのSizeを2にし、WallタグとGoalタグをレイが衝突する相手として設定します。
Ray Lengthを10にしレイの長さを調節します。
Stacked Raycastsはレイの過去のデータを何個分保持するかなのでBehavior ParametersのVector ObservationsのStacked Vectorsで指定した5と同じ数値分保持出来るようにしました。
シーンビューで見ると以下のような感じでレイが飛んでいるのがわかります。

これでエージェントキャラクターが出来ました。
ImitationLearningCharacterゲームオブジェクトの位置を変更しGoalゲームオブジェクトと反対の方に移動させます。
Goalスクリプトの作成
キャラクターがゴールエリアに入ったら報酬を与えてエピソードを終了させる必要があります。
なので、新しくGoalスクリプトを作成し、Goalゲームオブジェクトに取り付けます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | using System.Collections; using System.Collections.Generic; using UnityEngine; public class Goal : MonoBehaviour { [SerializeField] private ImitationLearningCharacter imitationLearningCharacter; public void OnTriggerEnter(Collider other) { if (other.tag == "Player") { imitationLearningCharacter.AddReward(1f); imitationLearningCharacter.EndEpisode(); } } } |
インスペクタでimitationLearningCharacterにImitationLearningCharacterゲームオブジェクトを設定します。
OnTriggerEnterメソッドでPlayerタグを持つコライダが侵入したらエージェントに報酬を与えてエピソードを終了させます。
カメラにエージェントキャラクターを追尾させる
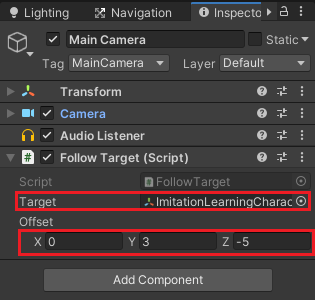
デモファイル作成時にカメラがキャラクターを追尾してくれると楽なのでMain CameraゲームオブジェクトのインスペクタのAdd Componentの検索窓にfollowと入力し、出てきたFollow Targetコンポーネントを取り付けます(UnityのStandard Assetsを入れていないとFollow Targetはありません)。
TargetにImitationLearningCharacterゲームオブジェクトをドラッグ&ドロップし、Offsetにオフセット位置を設定します。
デモファイルを作成する
学習環境の舞台とエージェントが出来たので実際に自分でキャラクターを操作してデモを作成します。
Unityエディターのプレイボタンを押してキャラクターを操作し、障害物をジグザグに移動し、ゴールエリアに到達するということを20回ほど繰り返し実行します。
移動するルートは全て同じにします。
以下のような感じで繰り返します。
20回ほどエピソードを実行したらUnityのエディターボタンを押して記録を終了します。
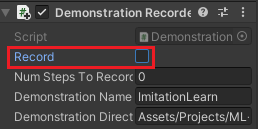
学習中にも記録しないようにImitationLearningCharacterのDemonstration RecorderのRecordのチェックをあらかじめ外しておきます。
Unityエディターの実行を終了してすぐにはデモファイルは作成されませんが、少し待つとDemonstration RecorderのDemonstration Directoryに指定した場所にデモファイルが作成されます。
デモを使用した学習用設定ファイル
デモファイルを使用して学習をさせる場合の設定ファイルにいくつかの項目を追加します。
設定ファイルはML-AgentsのツールキットのサンプルのPushBlockの模倣学習用の設定ファイルを変更して使う事にします。
まだダウンロードしていない方は以下のCodeからZIPファイルをダウンロードしてデスクトップにすべてのファイルを展開します。
デスクトップにML-Agentsツールキットのrelease8をファイル展開しているとすれば以下のフォルダにPushBlock.yamlファイルがあるのでデスクトップにそのファイルをコピーし、名前をImitationLearningCharacter.yamlにします。
C:\Users\ユーザー名\Desktop\ml-agents-release_8\ml-agents-release_8\config\imitation
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | behaviors: ImitationLearningCharacter: trainer_type: ppo hyperparameters: batch_size: 128 buffer_size: 2048 learning_rate: 0.0003 beta: 0.01 epsilon: 0.2 lambd: 0.95 num_epoch: 3 learning_rate_schedule: linear network_settings: normalize: false hidden_units: 256 num_layers: 2 vis_encode_type: simple reward_signals: gail: gamma: 0.99 strength: 1.0 encoding_size: 128 learning_rate: 0.0003 use_actions: true use_vail: false demo_path: C:/Users/ユーザー名/Documents/BlogProject(2020)/Assets/Projects/ML-Agents/ImitationLearning/Demos/ImitationLearn.demo keep_checkpoints: 5 max_steps: 15000000 time_horizon: 64 summary_freq: 5000 threaded: true behavioral_cloning: demo_path: C:/Users/ユーザー名/Documents/BlogProject(2020)/Assets/Projects/ML-Agents/ImitationLearning/Demos/ImitationLearn.demo steps: 0 strength: 1.0 samples_per_update: 0 |
設定項目の詳細についてはUnityのGitHubのマニュアルを参照してください。
今回の場合はデモのアクションを模倣させたいのでreward_signalsのgailのuse_actionsをfalseにしました。
demo_pathはデモファイルまでのパスを指定します。
behavioral_cloningは行動のクローンに関する設定でdemo_pathでデモファイルへのパスを指定し、stepsを0にするとトレーニングの実行全体にわたって一定の模倣を行うようです。
samples_per_updateも0にすると各更新ステップですべてのデモをトレーニングするようです。
色々設定を変えて試す必要がありそうですね・・・・((+_+))
学習の実行
設定ファイルが出来たので学習を開始してエージェントの動きを確認してみます。
前回の記事と同様にヒエラルキーのEnvironmentを選択し、Ctrl+Dキーを押して複製し10個の同じ学習環境を作成します。

Anacondaのコマンドプロンプトでコマンドを実行
AnacondaのコマンドプロンプトでML-Agentsの環境をアクティブにし、デスクトップに階層を移動した状態で以下のようにコマンドを打ちます。
mlagents-learn ./ImitationLearningCharacter.yaml –run-id ImitationLearningCharacter01
コマンドを実行してUnityのエディターのプレイボタンを押せという表示がされたらUnityエディターのプレイボタンを押し学習をさせます。
今回20回ほどのエピソードを実行したデモを使って学習させたモデルをBehavior ParametersのModelに設定して実行すると以下のようになりました。
20回ほどしかエピソードを実行していなかったり設定ファイルのパラメータの影響もあるのかデモとまったく同じに学習するということは出来ませんでしたが、ジグザグに動いてゴールに到達するという感じは学習してくれたのではないかと思います。
終わりに
今回の模倣学習を使えば例えばゲームプレイの見本の動きとかを作成するとき使えそうですね。
対戦ゲームの敵の動きを模倣学習を使ってどんどん強くさせたモデルを作るというのも出来るかもしれません。
んーしかし、まだまだ使いこなせないなぁ・・・・(´Д`)

